If you’re a Python developer, we invite you to join us in making sofastats_lib the best Python statistics library it can be. Even if you don’t have any other contributions to make, we’d really welcome your GitHub stars to help promote the project. We’d also welcome help improving the developer experience. Any feedback on how we can do that would be welcome. Our attitude: if anything is confusing, that’s on us not you.
Repo url: https://github.com/sofastats/sofastats_lib.
Archive for the ‘statistics’ Category
Join the sofastats_lib community
Saturday, February 28th, 2026Friendly Python Statistics Library Launched
Sunday, January 25th, 2026Trusted statistical reporting is now available in the convenient form of a Python library. Welcome to SOFA Stats – No Sweat Stats!
Perhaps you need to run an ANOVA, or a correlation analysis. Or you want to display your data as Box Plots, or nested Cross Tab tables.

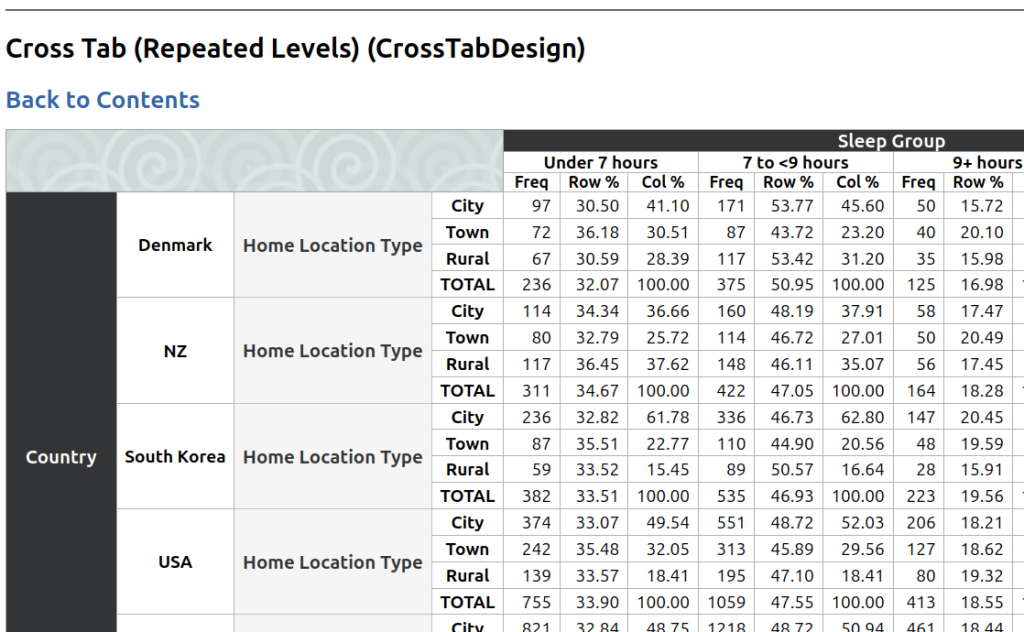
sofastats_lib can help. Look at the Output Gallery to see what is available. Here is the output of a simple Cross Tab table (based on synthetic demonstration data):
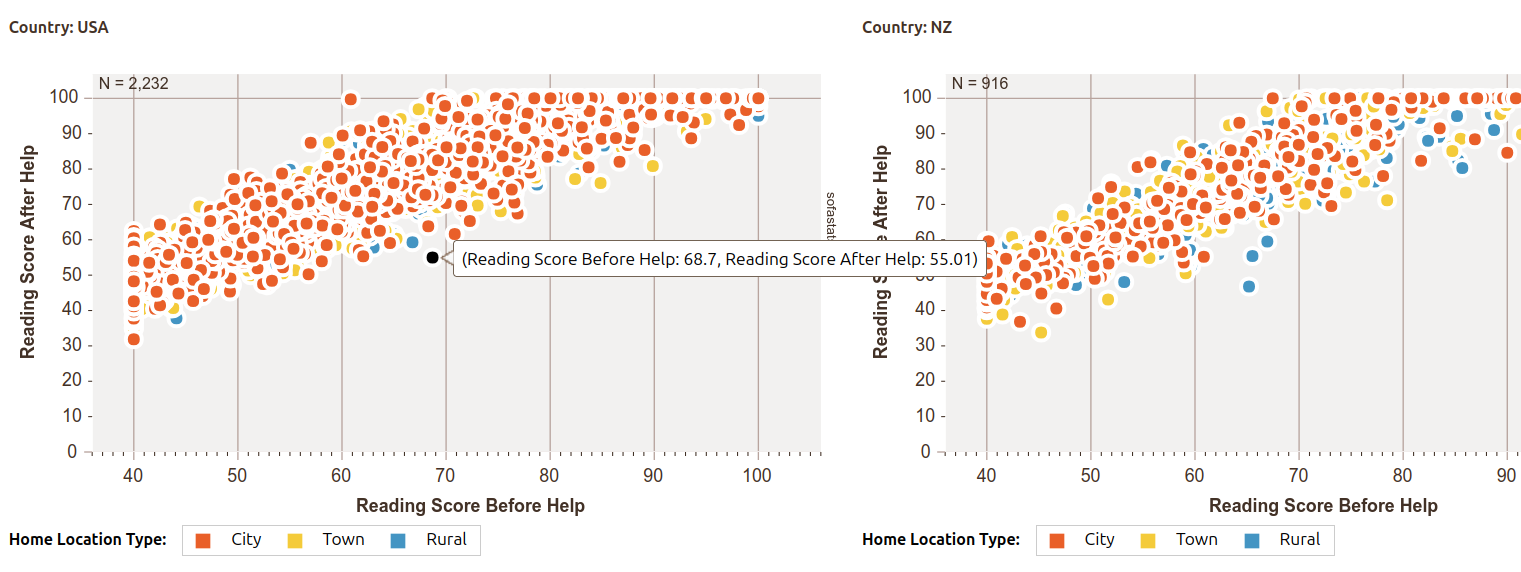
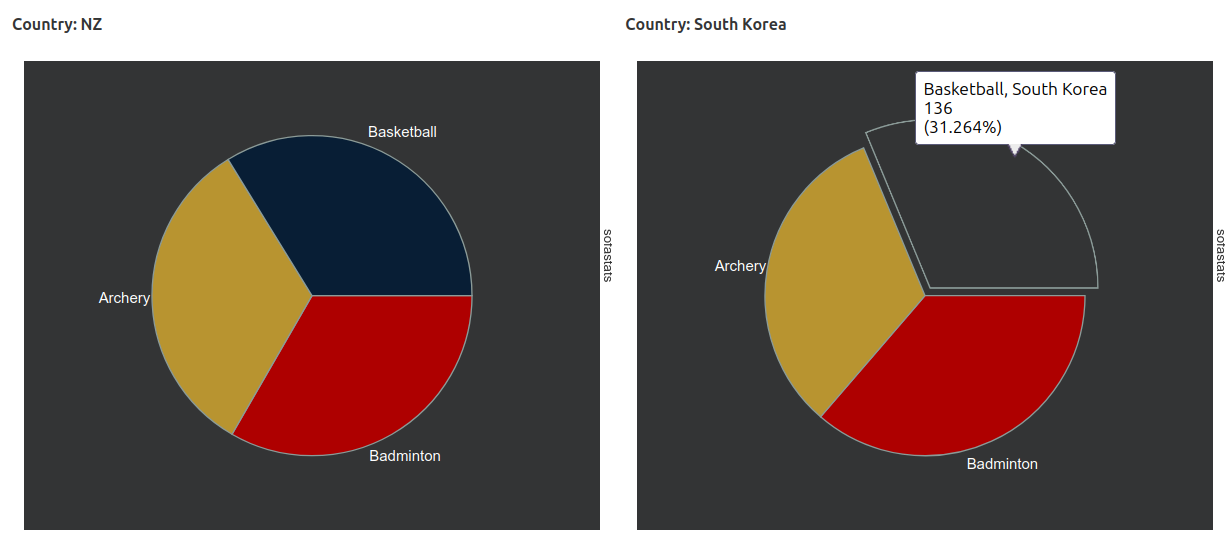
And here’s a preview of some of the charting options (also using synthetic data):

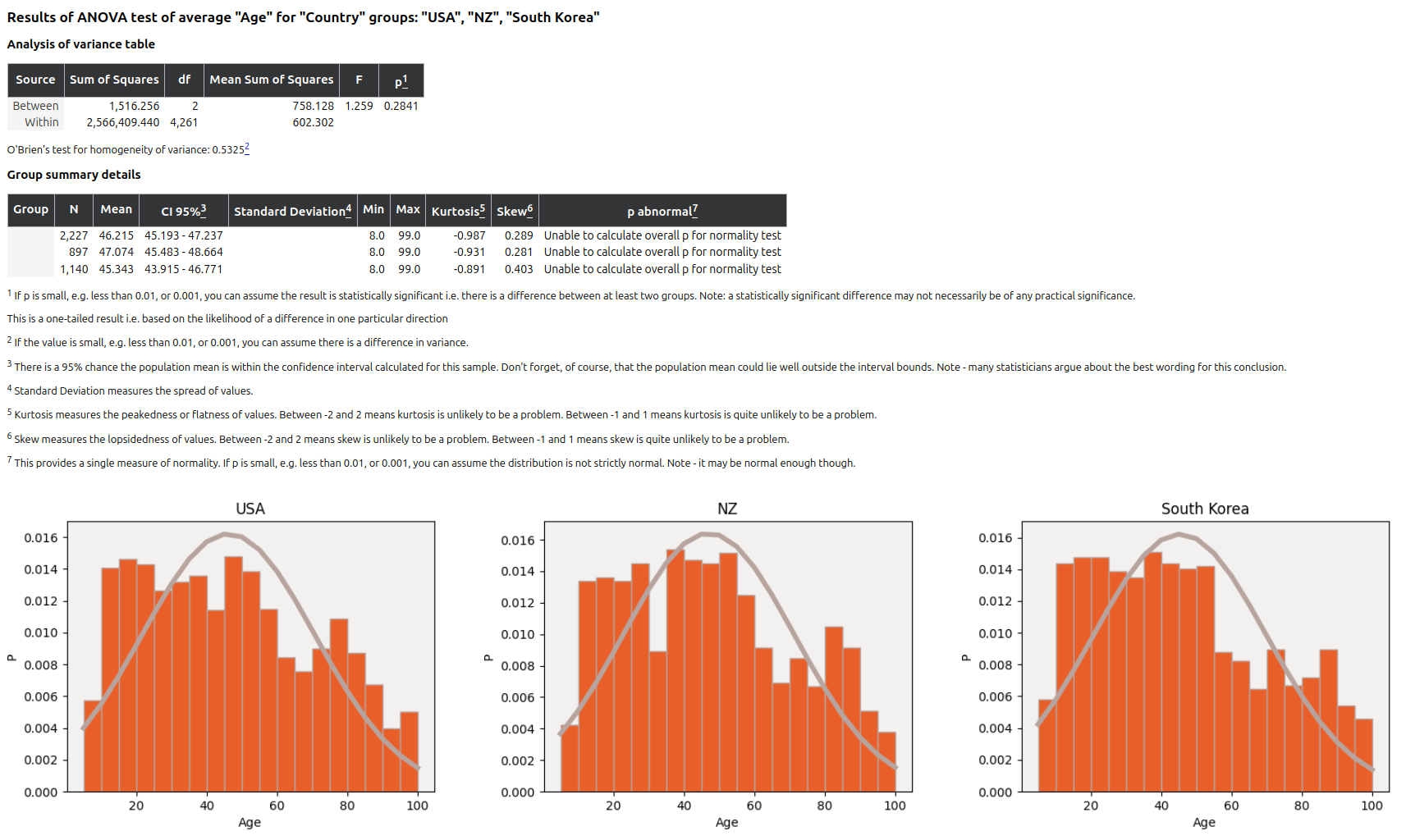
And the existing ANOVA documentation (once again, using synthetic data):
The full API is documented here: https://sofastats.github.io/sofastats_lib/API/ and there is a simple guide to making and reusing your own styles.
The easiest option is to start with a CSV. Just make sure it is long format not wide format (see Data Preparation).
sofastats_lib is based on the tried-and-true SOFA Statistics desktop application but can be used like any other Python library.
You can add it to your project in the usual way e.g. uv add sofastats_lib. Friendly installation and usage instructions are available at https://sofastats.github.io/sofastats_lib/
Let us know what you think of sofastats_lib. We can be contacted at grant@sofastatistics.com or you can add issues to the GitHub project. And please spread the word.
Maintenance Mode & SOFA Lite
Saturday, January 7th, 2023SOFA Statistics is now in stable, maintenance mode. New releases are mainly for bug fixes.
If you have been having problems running SOFA on Ubuntu / Debian / Linux check out the new deb and archive downloads at https://www.sofastatistics.com/downloads.php
Alongside SOFA Statistics I have started SOFA Lite https://github.com/grantps/sofalite. This is an almost complete re-write using some of the latest Python 3 language features and a new code architecture. It is called SOFA Lite because I am stripping out some features that were painful to maintain but were of limited value to most users.
One design goal for SOFA Lite is to make it super-easy to run analyses from Python scripts rather than just via the GUI.
Another goal is to significantly reduce the complexity of packaging SOFA Lite for different operating systems. For example, 90% of the pain of packaging SOFA Statistics has related to its image processing libraries, none of which are really needed now that user-friendly screen-shot software is so widely available. I would love to be able to release a version of SOFA (Lite) that works on the latest versions of the Mac OS (alongside Windows and Linux) and this looks like a good way of making that possible.
So onwards and upwards again 🙂
Nearly ready to release 1.5.0
Monday, April 29th, 2019Version 1.5.0 is nearly ready to release and not before time ;-). The last release was 1.4.6 in January 2016 but the time since then has not been wasted. Here are some of the changes ready to go:
- SOFA will be able to display worked examples for the following statistical tests:
- Mann-Whitney U
- Wilcoxon’s Signed Ranks
- Spearman’s Rho
- Pearson’s Chi Square
- It will be possible to choose the number of decimal places to show in report tables and charts
- SOFA will be able to display counts or percentage separately on pie charts
- There will be better smoothed line will be displayed for line charts
- Better visual separation of subtables
- Charts will be able to show N
- Improvements to darker themes
- Numerous bug fixes
Under the hood, SOFA has had some major changes:
- Python 3.6+ (Linux) / 3.7 (Windows)
- wxPython GUI toolkit is 4.0 (up from 2.8)
Sadly, the 1.5.0 release will not include a Mac package but later versions might do depending on practical considerations and offers of packaging help from Mac users. A deb package is already generated for Ubuntu / Debian. A Windows package is nearly ready – SOFA works on Windows 10 and all the dependencies have been baked into an executable ready for the final stages of packaging.
It is expected there will be a few minor bugs slipping through given the scale of the changes underneath but the plan is to quickly release 1.5.1 with these mopped up.
Great new SOFA teaching resource
Saturday, January 28th, 2017Thanks to George Self there is a great new teaching resource available for SOFA users. See https://goo.gl/4lpIaO Here is George’s announcement repeated from the discussion group:
I teach an undergrad research methodology class and wrote a SOFA-based lab manual for that class that some of you may be interested in. You can find the manual and the data sets at https://goo.gl/4lpIaO.
The manual has ten chapters:
- Introduction (data types, normal distribution, kurtosis, skew, null hypothesis, downloading/installing SOFA, recoding data)
- Central Measures (mean, median, mode)
- Data Dispersion (range, quartiles, standard deviation)
- Visualizing Dispersion (box charts)
- Frequency Tables (frequency tables, crosstabs, complex crosstabs)
- Visualizing Frequency (histogram, bar chart, clustered bar chart, pie chart, line graph)
- Correlation (pearson’s r, spearman’s rho, significance, scatter plots)
- Regression
- Hypothesis Testing: Nonparametric Statistics (SOFA Statistics Wizard, Kruskal-Wallis H, Wilcoxon Signed Ranks, Mann-Whitney U)
- Hypothesis Testing: Parametric Statistics (ANOVA, t-test-Independent, t-test-Paired)
There are also two appendices, the first is a data dictionary for each of the data sets used and the second covers the various report generating features of SOFA.
The lab manual covers all of the functions and features of SOFA, but in the context of a lab where those functions are practiced rather than just described. The manual also includes a lot of information about how the various statistical measures are used (for example, the difference between correlation and causation). No math knowledge beyond simple high school algebra is assumed on the part of the student and each of the labs includes a “deliverable” activity so instructors can use this as part of a class.
I’ve printed this manual under Creative Commons-BY-ShareAlike so please feel free to use this in any way you want. Of course, I’m also happy to receive comments that could help me improve this manual in the future.
–George
Please give the resource a spin and provide George with any feedback that can improve/refine it. Once again, thanks George for making this available to the community 🙂
What might be coming next
Wednesday, April 20th, 2016Python 2 is reaching its End Of Life (EOL) in 2020 so sometime before then I will want to shift SOFA to Python 3. I much prefer Python 3 but the main thing will be the libraries SOFA relies on to operate – especially on Windows and Mac.
Speaking of Mac, I am finding it very time-consuming supporting the platform. Not to enable SOFA’s core functionality to work but for the image processing libraries (esp convert and gs). Along the way I have spent countless weekends compiling using homebrew etc. Slow, tricky, and often fruitless. And it is difficult to test. I only have access to a Snow Leopard machine (virtualised to allow revert to snapshot) and that is no longer very relevant to what people need for newer versions of OS X. Some very kind people have offered to help with testing (thanks!) but the problem seems to be the packaging steps. Maybe what I need to do is ask the people who volunteered if any of them are able to compile convert and gs for me on their machines. I can then just include those versions in my packages and hopefully everything works.
A final work item is to add a Fisher’s LSD test. A friend is helping with this.
1.4.6 Adds basic time series
Friday, January 1st, 2016SOFA line charts and area charts now treat dates as dates in the x-axis which makes it easier to look at time series data.

New option added to interface

Time series selected – X-axis date aware

Time series not selected – X-axis not date-aware

Example time series chart
Additional improvements include:
- Better error message when not enough values in group to run analysis e.g. ANOVA.
- Better handling of precision in p-value results displayed.
- Better handling of dates pre-1900.
- Better messages to user about potentially excessive categories in charts.
- Add support for float years as date values for time series.
- Add support for specifying port connecting to postgresql.
- Allows boxplots when fewer values to display.
And there were two other changes:
- Removed broken google docs integration – just as easy to manually download and import normally.
- Removed two pop-ups – no longer needed.
There are also a number of bug fixes:
- No longer a missing legend in multiseries scatterplots just because the first scatterplot only had one series of data.
- Fixed bug with saving database connection details when a number involved (port).
- Fixed PostgreSQL bug when saving connection without password – now succeeds rather than failing silently.
- Fixed MySQL bug with adding rows.
- Fixed bug in Windows with checkboxes not enabling/disabling properly unless panels refreshed.
1.4.5 More box plot options
Saturday, August 15th, 2015There are several ways of doing box plots. Some show outliers, some don’t. Some set the whiskers at the min and max values, some don’t. Until now, SOFA kept it simple by only allowing one approach. But sometimes a little more flexibility is needed. So now users can choose between three options:
Option 1) This is the default. Outliers are displayed. Lower whiskers are 1.5 times the Inter-Quartile Range below the lower quartile, or the minimum value, whichever is closest to the middle. Upper whiskers are calculated using the same approach.
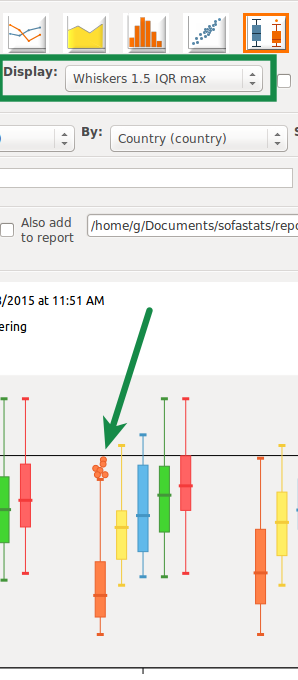
Option 2) Outliers hidden. Lower whiskers are 1.5 times the Inter-Quartile Range below the lower quartile, or the minimum value, whichever is closest to the middle. Upper whiskers are calculated using the same approach.

Option 3) Whiskers are at the minimum and maximum values.

And SOFA displays a small note at the bottom of each box plot so it is clear what approach has been used.
Additionally version 1.4.5 adds:
- ODS importing can now cope with repeated column names.
- Better error message when unable to get regression line details because of limited variability.
And there are numerous bug fixes as well:
- Fix bug when problem with imported data.
- Fix to title and date concatenation code so doesn’t break when title has non-ascii characters e.g. in Spanish (affecting Windows and Mac)
- Reordered regression line plotting in js so appears on top of dots.
- Added zero division error trap to spearman’s test error output.
- Fixed bug which prevented ods_reader from importing repeating rows at the end of a spreadsheet. Only repeated empty rows at the end are considered the end of the data.
- Properly handle all read operations on internal-use text files e.g. proj, css etc. Can cope with a utf-8 BOM (only) to cope with Windows Notepad editing. Breaks if other encodings used which is fair enough.
We hope you like the latest version.
Version 1.4.4 good for Mac Users
Monday, May 11th, 2015Mac users can finally export output in PDF format including individual charts and report tables. And depending on the version of OS X Mac users will also be able to export as PNG images. Ensuring image exporting works across multiple versions of OS X is an ongoing project of work which users can help with if interested.
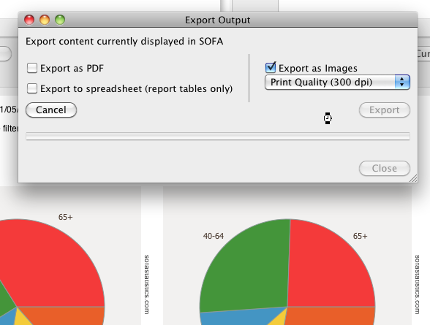

Users needing to produce monochrome output for publication will like the addition of a new monochrome theme.

All New Features in 1.4.4:
- Mac users can export output in PDF format (and PNG depending on version of OS X).
- Added new monochrome theme.
- Chi Square proportions output much easier to interpret successfully.
- The name of the grouping variable is now displayed when running comparisons of groups e.g. Country if comparing Italy and Germany.
- Exporting to spreadsheet detects if too many fields for xls output and informs user that only csv will be generated. Also truncates table name so worksheet name not too long.
- Import dialog only displays file types suitable for importing.
- Added message to let user know spreadsheet creation being skipped if no report tables to export.
- More user help on need for raw data (not pre-summarised) and long-format vs wide-format data as appropriate.
- Code reorganisation to make it possible for SOFA to be called in GUI form by external code GUI code.
- Scripts are now easier to use for standalone purposes.
- Added note about treatment of datetime data as categorical by SOFA for purposes of statistical tests.
- When exporting to spreadsheet and csv changes reserved sofa_id field name to was_sofa_id so it is OK to reimport after changes.
- More informative for larger range of potential problem e.g. database engine not functioning.
Bug Fixes:
- Fix bug resulting in Pearson’s r being displayed instead of Spearman’s rho.
- Fixed bug on some systems when saving a worksheet with spaces in name.
- Prevented numerous bugs related to quoting table names, fully qualified file names etc.
- Fixed bug with misuse of escape_pre_write on python code rather than normal content.
- Skew, and normality test now cope with the nan issue better e.g. sqrt of a negative number. Just says unable to calculate instead of displaying nan (not a number). skewtest function now copes with negative number as input to square root.
- Fixed bug when importing NaN text – now treated as a missing value in a numeric field.
- Removed bug which sometimes prevented Mac users from being able to successfully change the report name.
- Stopped making export folder if no output to export into it.
Importing tab-separated files and more
Saturday, March 15th, 2014SOFA 1.4.3 now lets you import directly from tab-separated/tab-delimited files.
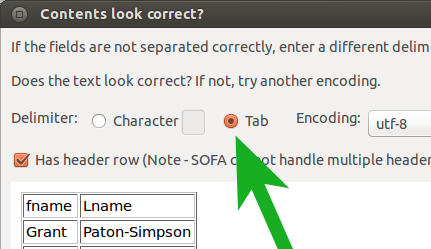
Another change is less momentous but should really please people doing lots of row stats reports. As SOFA gained more measures it became increasingly more effort to select individual measures one-by-one, checkbox by checkbox. Now there is a toggle button for Select All/Deselect All. Much better :-).

And the bonus themes are now part of the standard release making it easier than ever to make your charts and tables look good – I hope you like them.

One change that most users will never notice is better support for running SOFA via scripts. An exciting automation project is currently under development using this functionality and I hope to have some news to share soon.
Here’s the full list of changes:
- Can import tab-delimited data.
- More options for attractive charts and reports. Three new themes available – sky, prestige (screen), and prestige (print).
- Better support for automation (i.e. headless, running without GUI) esp in international context.
- Exporting to spreadsheet now relies on more robust code library (xlwt)
- Easy to select or deselect lots of row stats measures at once.
- Faster opening in many cases.
And the bug fixes:
- Minor tweak to PostgreSQL plug-in to handle timestamps without timezone.
- Resolved bug when SQLite numbers are stored in a non-numeric field and processed for Chi Square test.
- Importing csvs now copes better when only missing vals in sample of a field. Gives user the choice.
- Fixed bug when doing a Row Stats table with a rows variable e.g. by Gender and some of the fields can’t be calculated for some of the row categories.
- Headless importing now works in the event of inconsistent data types in fields.
- Headless importing now reads entire dataset rather than a sample to avoid need for (human) decisions.
- Scripts no longer rely on translated arguments. Much safer to use on other machines with different locales.
- Fixed circular import bugs which only became visible when other bugs occurred.